
In today’s digital landscape, the sheer volume of information within PDF documents can make it difficult to extract specific insights efficiently. The Langchain Chatbot, utilizing the OpenAI or HuggingFace API and advanced large language models (LLMs), transforms how we engage with PDF content. By blending natural language processing and machine learning techniques, this chatbot offers a sophisticated conversational interface for querying information across multiple PDFs.
This solution not only enhances search capabilities but also optimizes the information retrieval process. As the need for efficient data extraction grows in the business sector, tools like Langchain provide a competitive advantage by enabling rapid and precise access to vital information, thus conserving time and resources.
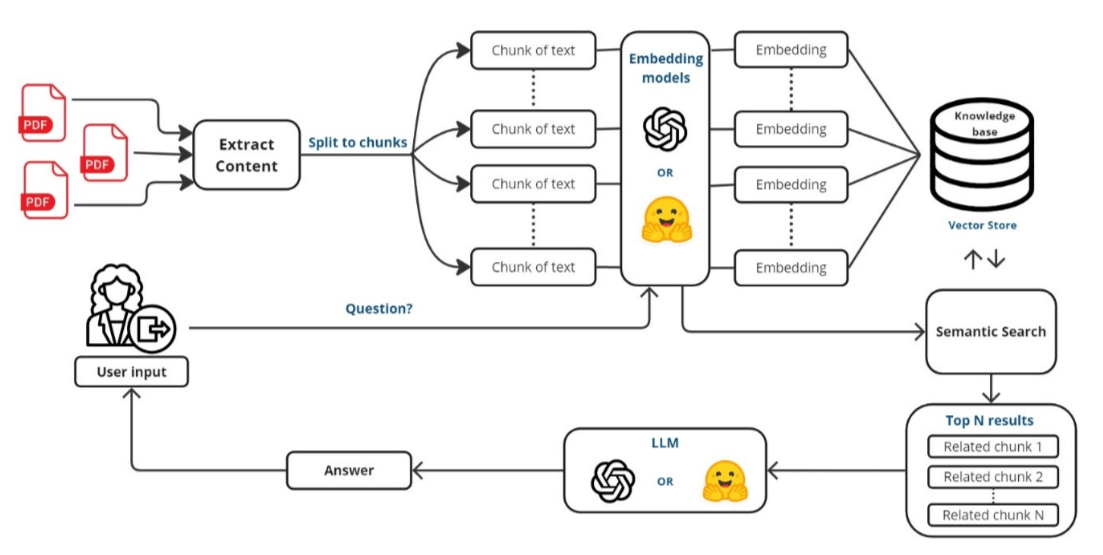
Overview diagram of application (Credit to Jeslur Rahman)
Here’s a step-by-step breakdown of how this application works
- Importing the necessary libraries

This step involves importing essential libraries and tools that are crucial for building the application. These include libraries for reading PDF files, handling natural language processing, embedding text, and creating conversational agents. Together, they enable the application to efficiently process and interact with the content of PDF documents.
- Reading and Processing PDF Files

The first major function within our application is designed to read PDF files.
When a user uploads one or more PDF files, the application reads each page of these documents and extracts the text, merging it into a single continuous string.
Once the text is extracted, it is split into manageable chunks.
Using the Text Splitter capability of the Langchain library, the text is divided into chunks of 1000 characters each. This segmentation helps in processing and analyzing the text more efficiently.
- Creating a Searchable Text Database and Making Embeddings

To make the text searchable, the application converts the text chunks into vector representations:
The application uses the FAISS library to turn text chunks into vectors and saves these vectors locally. This transformation is crucial as it allows the system to perform fast and efficient searches within the text.
Note that in this function, we can choose to use OpenAI Embeddings (a paid service) or import free Embeddings from HuggingFace’s Massive Text Embedding Benchmark (MTEB) Leaderboard.
- Setting Up the Conversational AI
The core of this application is the conversational AI, which uses ChatOpenAI or HuggingFaceHub models.
The app sets up a conversational AI agent using OpenAI’s GPT or HuggingFaceHub model and is designed to answer questions based on the PDF content that has been provided.
The solutions uses a set of prompts to understand the context and provide accurate responses to user queries. If the answer to a question isn’t available in the text, a response such as “answer is not available in the context” is returned ensuring that users do not receive incorrect information.
- User Input Handling
To process user questions and interact with the conversation chain:
This takes a user question as input and uses the conversation chain to generate a response.
- User Interaction (UI)

With the backend ready, we can use Streamlit to create a user-friendly interface.
Users are presented with a simple text input where they can type their questions related to the PDF content. The application then displays the responses related to the content of the PDF directly on the web page.
- Run the application
Save the code as app.py and then run the code using “streamlit run app.py’’. To recap, the solution demonstrates the following capabilities:- File Uploader and Processing: Users can upload one or more PDF files. The application processes these files on the fly, updating the database with new text for the AI to search.
- Ask questions: Once the PDF documents are uploaded, you can proceed to the main chat interface. Here, you can enter your questions or queries related to the content of the uploaded PDFs. The chatbot leverages natural language processing and machine learning techniques to understand and interpret your queries accurately.
- Receive answers: After submitting your questions, the chatbot immediately processes the information extracted from the PDF documents. It employs conversational retrieval techniques and the power of language models to generate relevant and context-aware responses. The chatbot strives to provide accurate and informative answers based on the content found within the PDFs.
Conclusion
Building an LLM-powered application to chat with documents offers a revolutionary way to interact with and extract information from large volumes of text, particularly within PDF files. By leveraging tools like Langchain, FAISS, and advanced language models from OpenAI or HuggingFace, this solution provides a powerful, user-friendly interface for querying document content.
This approach not only streamlines information retrieval but also enhances the accuracy and efficiency of data extraction processes. Whether in business, research, or other fields, the ability to quickly access and converse with document content gives users a significant edge, allowing them to make informed decisions faster. As AI-driven technologies continue to evolve, applications like this will become indispensable tools for navigating the ever-growing sea of digital information.
